图书馆VIP网络空间安全学院近日在代码漏洞检测方面发表了一项重要研究成果。软件漏洞对计算机系统、网络和数据的安全性和完整性构成了重大风险。2023 年,通用漏洞和暴露数据库 (CVE) 中公开报告了 28,902 个漏洞,数量惊人。PHP 被认为是 Web 应用程序中最流行和使用最广泛的语言,为排名前 1000 万的网站中的近 80% 提供支持,容易受到常见的 Web 安全漏洞的影响。传统的漏洞检测方法往往受限于规则库的全面性和准确性,导致误报和漏报的发生率较高。为了克服这一缺陷,研究人员开始转向基于深度学习或LLM的自动化漏洞检测方法。然而,由于漏洞样本的获取和标注难度较大,目前的漏洞检测方法在数据收集和处理方面存在明显缺陷,进而导致模型难以学习到漏洞的特征信息,在可用性和泛化性方面的存在严重不足。
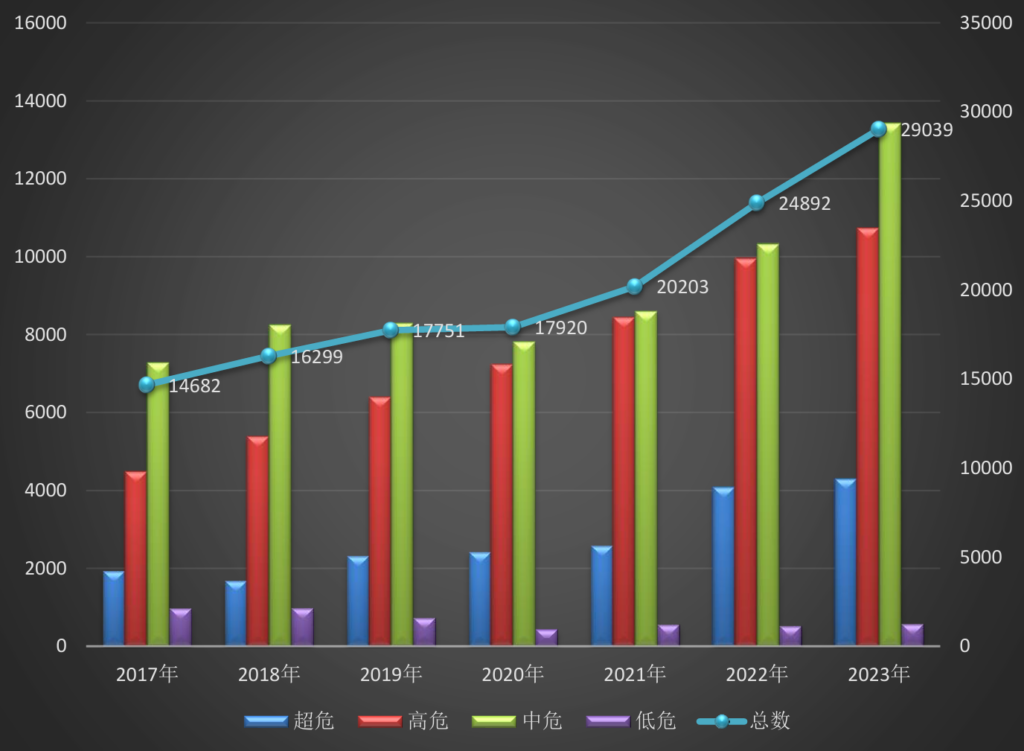
图 1 漏洞数量变化趋势
网络空间安全学院研究生曹笛对目前基于深度学习或LLM的自动化漏洞检测方法进行了调研,并与中国电子科技集团公司电子科学研究院开展研究交流,所取得的研究成果以论文形式发表于The 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP 2024),论文题为“RealVul: Can We Detect Vulnerabilities in Web Applications with LLM?”。现有的基于漏洞修复的数据集收集方法已经被证实在漏洞检测领域存在准确性、唯一性等方面的问题,并且这种方法可能会引入其他问题,例如在代码中包含未知漏洞。已有的漏洞检测方法缺乏针对PHP的研究,并且多数过度信任数据集,缺乏对样本的预处理过程。针对这些问题,研究团队提出了一种基于LLM的漏洞数据集提取和检测PHP漏洞方法,在自动化代码漏洞检测领域取得了更好的表现。
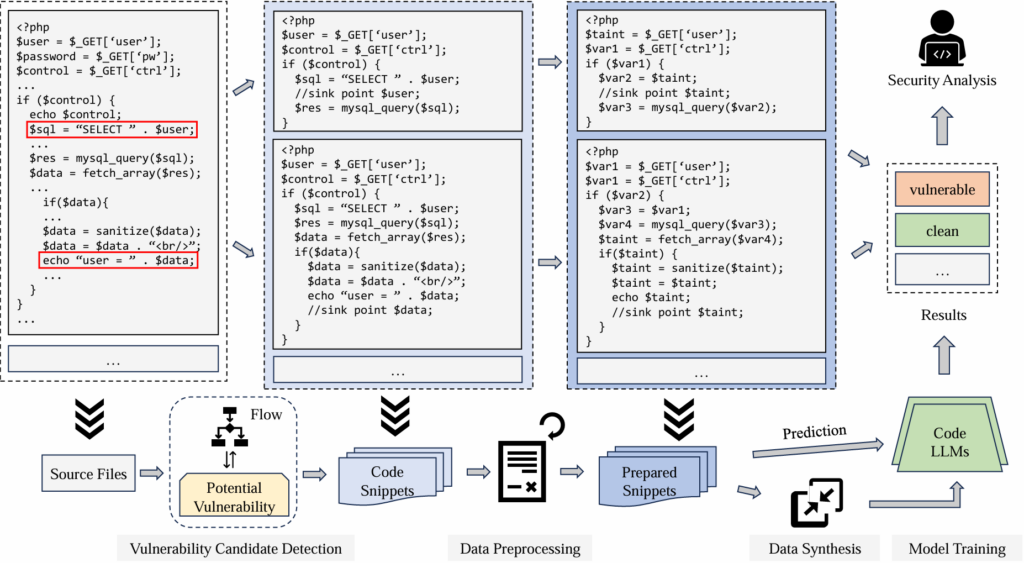
图 2 代码漏洞检测方法框架
在该研究成果中,研究团队提出了一种候选漏洞检测的方法,通过定位潜在漏洞源并进行程序切片获取初步的漏洞样本。具体地,团队首先利用领域专业知识和启发式规则匹配来识别源文件代码中可能引发漏洞的语句和变量,并标记为潜在漏洞源。随后生成源文件代码的抽象语法树(AST)、控制流和数据流,从而识别每个潜在漏洞源相关的代码语句,提取整理为初步的漏洞样本。
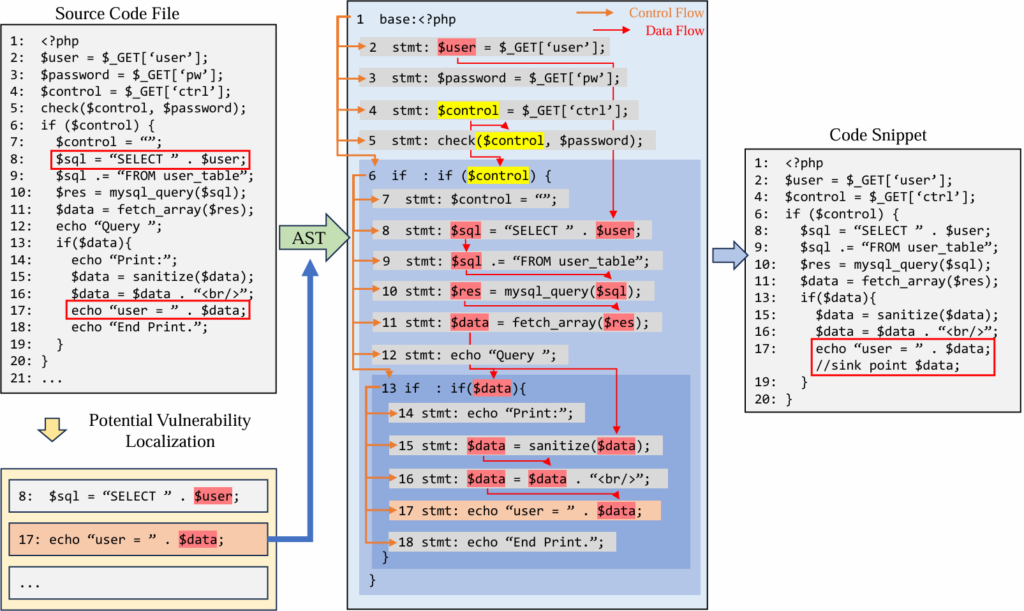
图 3 候选漏洞检测流程
初步获取的漏洞样本数据集中仍然存在信息冗余、样本不唯一等问题,因此团队继续通过标签化、标准化和去重完成样本的预处理。过于基于LLM进行漏洞检测的研究为了尽可能保留语义信息,往往会保留代码注释、用户定义的变量名等,然而研究团队发现,去除这部分的信息往往会取得更好的效果。因此,团队在去除代码注释等内容后,通过映射重写变量名来标准化代码,并在比对分析后删除高度重复的漏洞样本以确保样本的唯一性。此外,团队提出一种新的数据合成方法,通过将漏洞样本随机插入项目代码后重新提取样本,以获取足量的数据集用于微调模型。
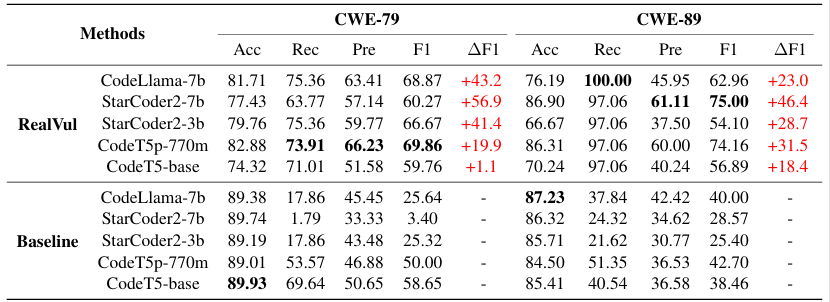
图 4 使用不同数据源的样本验证泛化性的结果
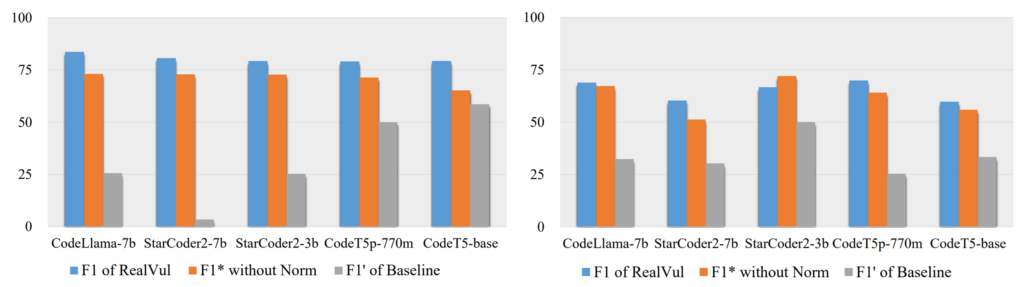
图 5 针对标准化的消融学习验证
研究团队在多个代码大模型上的开展综合实验,并与已有的研究方法基线进行比对。实验结果充分表明团队提出的方法在针对PHP代码的自动化漏洞检测方面优于已有的方法,在可用性和泛化性方面都有更好的表现,并展现出基于漏洞修复的样本提取方法在漏洞检测领域的不足。此外,团队通过取消研究方法中的标准化步骤进行对比实验,验证了标准化步骤在样本预处理中的必要性。